It happens that one want to protocol all changes of records of a table in the same table. This by using two timestamp columns „valid_from“ and „valid_to“. So that there is always exactly one version of a record for a given time.
As part of a data migration in a project, I was faced with a situation that I have different versions that have the same content. Let me illustrate this with an example:
create table tbl_a (
id number
,valid_from timestamp(6)
,valid_to timestamp(6)
,element_id number
,k_type varchar2(10)
);Fill the table with few columns
insert into tbl_a
select 123456 id,
systimestamp + numtodsinterval(1, 'SECOND') +
numtodsinterval(rownum - 1, 'MINUTE') valid_from,
systimestamp + numtodsinterval(rownum, 'MINUTE') valid_to,
case when mod(rownum,12) in (4,5,6) then 123 when mod(rownum,12) in (7,8,9) then 124
when mod(rownum,12) in (10,11,0) then 125 else null end element_id,
case when mod(rownum,12) in (4,5,6) then 'NP' when mod(rownum,12) in (7,8,9) then 'JP'
when mod(rownum,12) in (10,11,0) then 'KB' else null end k_type
from dual
connect by level < 25;
commit;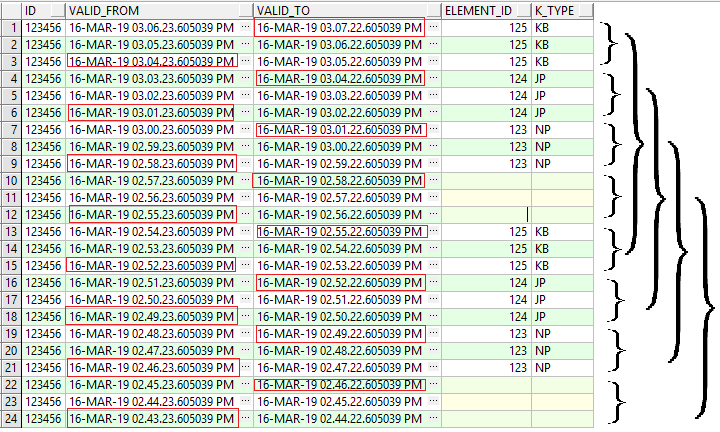
In this example, we see that we have six versions of each record.
But only two versions, correspond to a real change. So the goal is to remove the non-real changes to each record and the values of „valid_from“ and „valid_to“ need not have a gap. The right „valid_from“ and „valid_to“ are marked in red.
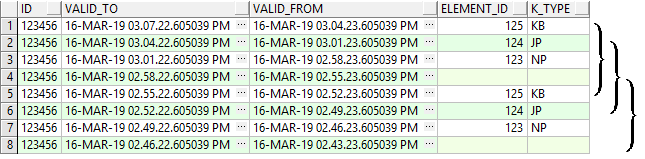
with the right version Begin and end
This can be achieved with the following SQL:
SELECT id,
MAX(valid_to) valid_to,
MIN(valid_from) valid_from,
element_id,
k_type
FROM (SELECT id,
valid_to,
valid_from,
element_id,
k_type,
ROW_NUMBER() OVER(PARTITION BY id ORDER BY valid_to) - ROW_NUMBER() OVER(PARTITION BY id, element_id, k_type ORDER BY valid_to) rrr
FROM (SELECT id,
valid_to,
valid_from,
element_id,
k_type,
LEAD(k_type || element_id, 1, 'x') OVER(PARTITION BY id ORDER BY valid_to) R,
LAG(k_type || element_id, 1, 'x') OVER(PARTITION BY id ORDER BY valid_to) RR
FROM tbl_a T
ORDER BY valid_to) S
WHERE (NVL(R, 'y') <> NVL(RR, 'y') OR
NVL(r, 'y') <> NVL(k_type || element_id, 'y'))) Q
GROUP BY id, element_id, k_type, rrr
order by 3 desc That was just an example. In my case, the table consisted of several dozens of columns and has several millions of records.
You can use pl sql to dynamically generate this SQL for a general case.
