Today I want to discuss with you the effective way to get rid of most of data from a large table in oracle.
For example, if you need to delete 90 % of the data from a logging table or something like that.
A large table

•Black area contains unneeded data that should be deleted
•Green area contains data that is still needed
•White area unused space
Using Delete statement would most likely take an eternity and will generate a huge amount of REDO and UNDO (as we will see). Unnecessary REDO and UNDO represent only a stress for the entire database.
Usually Delete statement should be used only to remove a small amount of data.
Starting with the second version of Oracle 12 (12.2.0.1), oracle introduced an elegant way to achieve this, namely the DDL „alter table move“ was enhanced to move only a part of the data using where clause.
So, it is possible to move and reorg only the data that you need: for example, alter table large_table move including rows where id < 1000 (only data that meets this condition remains in the table)
Let’s create a test table
create table mytable as select id from dual connect by level < 101;
Using this new feature:
alter table mytable move including rows where id < 50;
This reorgs the table segment by keeping only data that meets the where clause.
It is even possible to delete all data (like truncate statement):
alter table mytable move including rows where 1=2;
no row meets this condition and consequently the table will be emptied.
This feature was only introduced in the version 12.2.
Does this mean that we must use a DML statement to delete data in versions older than 12.2 e.g., in 12.1 or 11.2.0.4?
Certainly not.
There are many ways to achieve delete data without using DML.
I will show you another method based on the partition exchange.
Using partition exchange, doesn’t mean that the target table should be partitioned but we create a worktable that is partitioned, and we create a partition with only the data that shouldn’t be deleted, and we perform a partition exchange


We will test the new method and compare it to the method that uses partition exchange and to the method that uses DELETE statement.
We create a big table: The data we want to delete is uniformly spread over all blocks – just to make the test more realistic
CREATE TABLE big_tbl AS
SELECT ROWNUM ID,2022+MOD(ROWNUM, 10) YEAR, rpad(rownum,10,'x') col1, rpad(rownum,20,'y') col2 , rpad(rownum,30,'z') col3,SYSDATE + ROWNUM/24/60 col4,
rpad(rownum,50,'a') col5, rpad(rownum,100,'b') col6,rpad(rownum,100,'b') col7,rpad(rownum,100,'b') col8,rpad(rownum,100,'b') col9 FROM
(SELECT 1 FROM (SELECT 1 FROM dual CONNECT BY LEVEL < 11) CROSS JOIN (SELECT 1 FROM dual CONNECT BY LEVEL < 100001))
Check the number of rows:
SELECT /*+ parallel(t 4) */ YEAR,COUNT(*) FROM big_tbl t GROUP BY ROLLUP(YEAR) ORDER BY 1| Year | count |
| 2022 | 10000 |
| 2023 | 10000 |
| 2024 | 10000 |
| 2025 | 10000 |
| 2026 | 10000 |
| 2027 | 10000 |
| 2028 | 10000 |
| 2029 | 10000 |
| 2030 | 10000 |
| 2031 | 10000 |
| Total | 100000 |
Block to create nine tables as CTAS from big_tbl
DECLARE
TYPE t_numbers IS TABLE OF NUMBER;
v_years t_numbers := t_numbers(2022,2023,2024,2025,2026,2027,2028,2029,2030);
PROCEDURE ex_ignor_err(cmd VARCHAR2) IS BEGIN EXECUTE IMMEDIATE cmd; EXCEPTION WHEN OTHERS THEN NULL; END;
PROCEDURE LOG(msg VARCHAR2) IS BEGIN dbms_output.put_line(msg); END;
BEGIN
FOR i IN 1..v_years.count LOOP
LOG(v_years(i));
ex_ignor_err( 'drop table tbl_' ||v_years(i) || ' purge') ;
EXECUTE IMMEDIATE( 'create table tbl_' || v_years(i) || ' as select /*+ parallel(t 4) */ * from big_tbl t');
END LOOP;
END;Check the size of the tables:
SELECT segment_name,bytes/1024/1024 size_in_mb FROM user_segments WHERE segment_name LIKE 'TBL%'| Table | Size in MB |
| TBL_2029 | 608 |
| TBL_2030 | 608 |
| TBL_2031 | 608 |
| TBL_2022 | 608 |
| TBL_2023 | 607 |
| TBL_2024 | 608 |
| TBL_2025 | 608 |
| TBL_2026 | 608 |
| TBL_2027 | 608 |
| TBL_2028 | 608 |
Deleting data using alter table move including rows
DECLARE
v_redo NUMBER;
v_undo NUMBER;
v_ela NUMBER;
TYPE t_numbers IS TABLE OF NUMBER;
v_years t_numbers := t_numbers(2022,2023,2024,2025,2026,2027,2028,2029,2030);
FUNCTION get_stat(p_name VARCHAR2) RETURN NUMBER IS
ret NUMBER;
BEGIN
EXECUTE IMMEDIATE 'select b.value from v$statname a join v$mystat b using(statistic#) where a.name = :1' INTO ret USING p_name;
RETURN ret;
END get_stat;
PROCEDURE LOG(msg VARCHAR2) IS BEGIN dbms_output.put_line(msg); END;
BEGIN
FOR i IN 1..v_years.count LOOP
v_redo := get_stat('redo size');
v_ela := dbms_utility.get_time;
v_undo := get_stat('undo change vector size');
EXECUTE IMMEDIATE 'alter table tbl_'||v_years(i) || ' move including rows where year > ' ||v_years(i);
v_ela := dbms_utility.get_time - v_ela;
v_redo := get_stat('redo size') - v_redo;
v_undo := get_stat('undo change vector size') -v_undo;
LOG(i*10 || '% ' || ' ' ||v_redo ||' ' || v_undo || ' ' || v_ela );
END LOOP;
END;The above block iterates over the nine test tables and delete each time 10% more data than the previous iteration. The get_stat method is used to calculate the amount of generated REDO/UNDO.
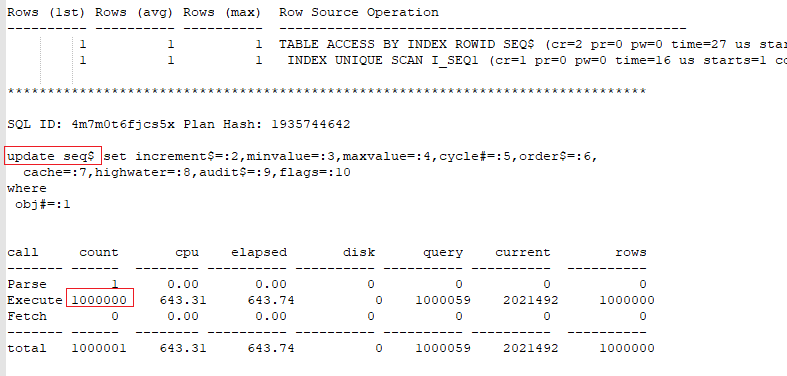
Deleting data using DML
DECLARE
v_redo NUMBER;
v_undo NUMBER;
v_ela NUMBER;
TYPE t_numbers IS TABLE OF NUMBER;
v_years t_numbers := t_numbers(2022,2023,2024,2025,2026,2027,2028,2029,2030);
FUNCTION get_stat(p_name VARCHAR2) RETURN NUMBER IS
ret NUMBER;
BEGIN
EXECUTE IMMEDIATE 'select b.value from v$statname a join v$mystat b using(statistic#) where a.name = :1' INTO ret USING p_name;
RETURN ret;
END get_stat;
PROCEDURE LOG(msg VARCHAR2) IS BEGIN dbms_output.put_line(msg); END;
BEGIN
FOR i IN 1..v_years.count -1 LOOP
v_redo := get_stat('redo size');
v_ela := dbms_utility.get_time;
v_undo := get_stat('undo change vector size');
EXECUTE IMMEDIATE ‘delete from table tbl_'||v_years(i) || ' where year > ' ||v_years(i);
commit;
v_ela := dbms_utility.get_time - v_ela;
v_redo := get_stat('redo size') - v_redo;
v_undo := get_stat('undo change vector size') -v_undo;
LOG(i*10 || '% ' || ' ' ||v_redo ||' ' || v_undo || ' ' || v_ela );
END LOOP;
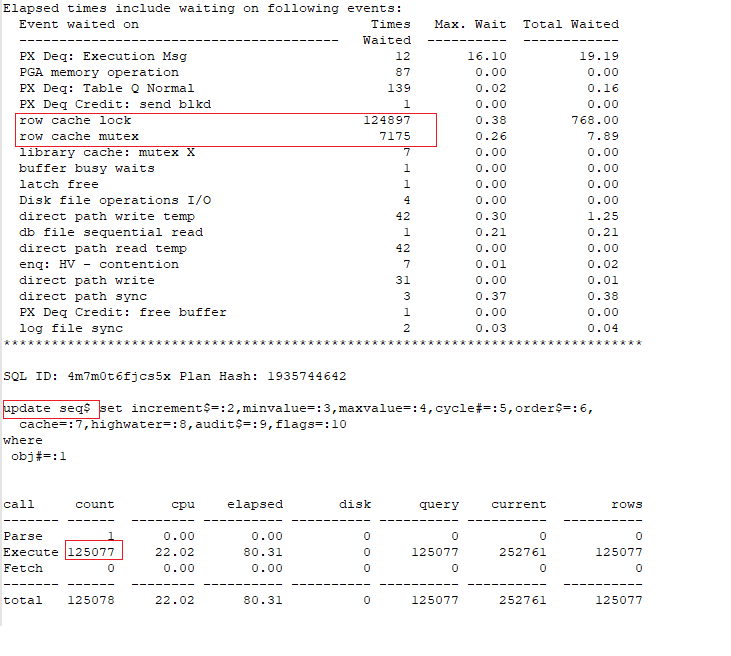
END;Deleting data using partition exchange
DECLARE
v_redo NUMBER;
v_undo NUMBER;
v_ela NUMBER;
TYPE t_numbers IS TABLE OF NUMBER;
v_years t_numbers := t_numbers(2022,2023,2024,2025,2026,2027,2028,2029,2030);
v_cols sys.odcivarchar2list;
v_get_cols VARCHAR2(4000);
FUNCTION get_cols RETURN VARCHAR2 IS
ret VARCHAR2(4000);
BEGIN
FOR i IN 1..v_cols.count LOOP ret := ret || v_cols(i) || ','; END LOOP;
RETURN RTRIM(ret,',');
END get_cols;
PROCEDURE LOG(msg VARCHAR2) IS BEGIN dbms_output.put_line(msg); END;
PROCEDURE pc_del_data_using_prtexchg(p_trgt_tbl VARCHAR2, p_where_cond VARCHAR2, p_tblspace VARCHAR2, p_dop VARCHAR2 DEFAULT '4') IS
v_sql VARCHAR2(32767);
v_tmp_tbl VARCHAR2(30) := 'tmp_tbl_to_purge_old_data';
BEGIN
BEGIN
EXECUTE IMMEDIATE 'drop table ' || v_tmp_tbl || ' purge';
EXCEPTION
WHEN OTHERS THEN
NULL;
END ;
v_sql := 'CREATE TABLE ' || v_tmp_tbl || ' ('||v_get_cols||')
partition by range ('||v_cols(1)||') (partition p0 values less than (maxvalue) tablespace '||p_tblspace||')
as ( select /*+ parallel(t '||p_dop||') */ * from '||p_trgt_tbl||' t '||p_where_cond||')';
EXECUTE IMMEDIATE v_sql;
v_sql := 'ALTER TABLE ' || v_tmp_tbl || ' EXCHANGE PARTITION p0 WITH TABLE ' || p_trgt_tbl ;
EXECUTE IMMEDIATE v_sql;
EXCEPTION
WHEN OTHERS THEN
LOG(SQLERRM);
RAISE;
END pc_del_data_using_prtexchg;
FUNCTION get_stat(p_name VARCHAR2) RETURN NUMBER IS
ret NUMBER;
BEGIN
EXECUTE IMMEDIATE 'select b.value from v$statname a join v$mystat b using(statistic#) where a.name = :1' INTO ret USING p_name;
RETURN ret;
END get_stat;
BEGIN
SELECT column_name BULK COLLECT INTO v_cols FROM user_tab_cols WHERE table_name = 'BIG_TBL' ORDER BY column_id;
v_get_cols := get_cols;
FOR i IN 1..v_years.count LOOP
v_redo := get_stat('redo size');
v_ela := dbms_utility.get_time;
v_undo := get_stat('undo change vector size');
pc_del_data_using_prtexchg('tbl_'||v_years(i), ' where year > ' ||v_years(i), 'USERS');
v_ela := dbms_utility.get_time - v_ela;
v_redo := get_stat('redo size') - v_redo;
v_undo := get_stat('undo change vector size') -v_undo;
LOG(i*10 || '% ' || ' ' ||v_redo ||' ' || v_undo || ' ' || v_ela );
END LOOP;
END;Elapsed time in ms to delete from a table with 1 Mio rows (600MB).
Alter table move vs partition exchange vs Delete
| MOVE | Partition Exchange | ||||
| MOVE_DOP 1 | MOVE_DOP 4 | PEXC_DOP 1 | PEXC_DOP 4 | Delete | |
| 10% | 8070 | 4300 | 11740 | 9920 | 5420 |
| 20% | 7240 | 3800 | 10910 | 8860 | 9350 |
| 30% | 6460 | 3550 | 10180 | 8460 | 12610 |
| 40% | 5930 | 3130 | 9440 | 7820 | 16540 |
| 50% | 5130 | 2800 | 8230 | 6930 | 18580 |
| 60% | 4580 | 2640 | 7720 | 6270 | 23570 |
| 70% | 3910 | 2370 | 6920 | 5700 | 27950 |
| 80% | 3340 | 1850 | 6510 | 4900 | 32270 |
| 90% | 2890 | 1560 | 5770 | 4510 | 46880 |

Alter table move vs partition exchange vs Delete
We see that using DML to delete a big amount of data is not suitable. The new feature is very performant, especially when parallel processing is used.
Let’s check the amount of generated REDO/UNDO
Amount of generated REDO/UNDO in MB – Deletion from a table with 1 Mio rows: 600 MB
| Redo_Delete | Undo_Delete | Redo_MOVE | Undo_Move | Redo_PEXC | Undo_PEXC | |
| 10% | 81856 | 63481 | 481 | 61 | 486 | 67 |
| 20% | 166274 | 127545 | 453 | 58 | 408 | 64 |
| 30% | 246739 | 191644 | 426 | 54 | 379 | 60 |
| 40% | 328479 | 255715 | 401 | 52 | 356 | 58 |
| 50% | 410338 | 319785 | 374 | 49 | 326 | 54 |
| 60% | 491963 | 383787 | 348 | 45 | 301 | 51 |
| 70% | 574941 | 447902 | 320 | 42 | 275 | 48 |
| 80% | 656880 | 511998 | 295 | 39 | 249 | 45 |
| 90% | 738101 | 576195 | 265 | 35 | 222 | 42 |




The new feature and the method using partition exchange hardly generate REDO/UNDO in contrast to the method using DML.
Same test using a table with 10 Mio rows (6GB)
Elapsed time to delete from a table with 10 Mio rows (6GB).
Alter table move vs partition exchange
| MOVE | Partition Exchange | |||
| MOVE_DOP 1 | MOVE_DOP 4 | PEXC_DOP 1 | PEXC_DOP 4 | |
| 10% | 84040 | 60370 | 133170 | 86090 |
| 20% | 70120 | 48910 | 107490 | 85520 |
| 30% | 59560 | 45040 | 90850 | 78610 |
| 40% | 53760 | 42210 | 83130 | 69570 |
| 50% | 52450 | 36210 | 77590 | 66380 |
| 60% | 43260 | 32750 | 73830 | 60630 |
| 70% | 37120 | 27480 | 67570 | 55770 |
| 80% | 33120 | 21520 | 61460 | 49840 |
| 90% | 27320 | 14750 | 54860 | 44020 |

Alter table move vs partition exchange
| Redo_MOVE | Undo_Move | Redo_PEXC | Undo_PEXC | |
| 10% | 1289 | 115 | 1242 | 121 |
| 20% | 1213 | 111 | 1188 | 117 |
| 30% | 1139 | 107 | 1109 | 113 |
| 40% | 1066 | 103 | 1016 | 109 |
| 50% | 989 | 99 | 943 | 105 |
| 60% | 914 | 95 | 868 | 101 |
| 70% | 841 | 91 | 792 | 97 |
| 80% | 782 | 95 | 720 | 93 |
| 90% | 564 | 65 | 513 | 70 |


The two methods hardly generate REDO/UNDO and are very fast.