Sequences are good choice to generate unique integers for populating primary key and foreign key columns. By using them it is guaranteed that two sessions do not pull the same value. Ensuring this could have a big price in terms of performance. Indeed a sequence is just a row in the seq$ table and every time a session tries to get the next value of the sequence, it should increment the highwater value. This means updating highwater column for the row of the sequence in the seq$ table. For that, the session needs to request a row lock. In parallel processing, this leads to poor performance.
But also in serial processing (Even if the session may only request the lock once for the whole work), the act to update the seq$ table for each used value of the sequence is very expensive. Therefore you should cache the sequence.
Cache specifies how many sequence numbers to preallocate and keep in memory.
Only when all values from the cache are used, the table seq$ is updated. This means the larger is the cache the fewer updates on the seq$ table take place. So if you want to insert millions of rows the cache should be at least 1000.
In my point of view, there is no problem with caching of 5000 values or more. Because only in event of an instance failure (power failure, shutdown abort), any unused values still in memory are lost.
Caching has also a positive impact on parallel processing. Even significantly better than serial processing.
By using the technique of directly calling the sequence in the DML statements, do not forget to increase the cache explicitly and reset it to the default value after the DML is finished.
Let see some examples:
--we create a sequence with no cache
create sequence my_seq increment by 1 nocache;
--we create two table a and b. Both with 1Mio records
create table a as select rownum id, decode(mod(rownum,2),0,null,rownum) id2 from (
(select * from dual connect by level < 1001 ) cross join (select * from dual connect by level < 1001));
create table b as select rownum id from (
(select * from dual connect by level < 1001 ) cross join (select * from dual connect by level < 1001));
-- we create an empty table
create table tbl_test_seq (id number, text varchar2(300));
-- we insert 1 Mio records in serial processing
-- and we enable event 10046
ALTER SESSION SET EVENTS '10046 trace name context forever, level 12';
insert /*+ append gather_plan_statistics */ into tbl_test_seq t
select nvl(a.id2,my_seq.nextval) ,lpad('xx',200,'y') text from a join b
on a.id = b.id;
commit;
ALTER SESSION SET EVENTS '10046 trace name context off';
Insert of 1Mio records in serial processing

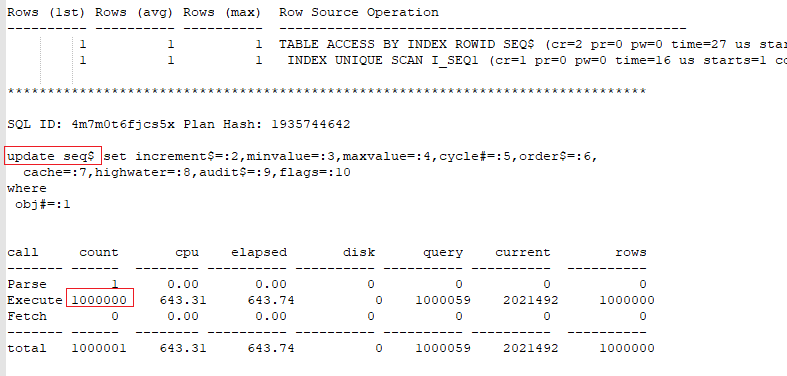
Insert 1Mio records in dop = 8. Trace for one process slave:

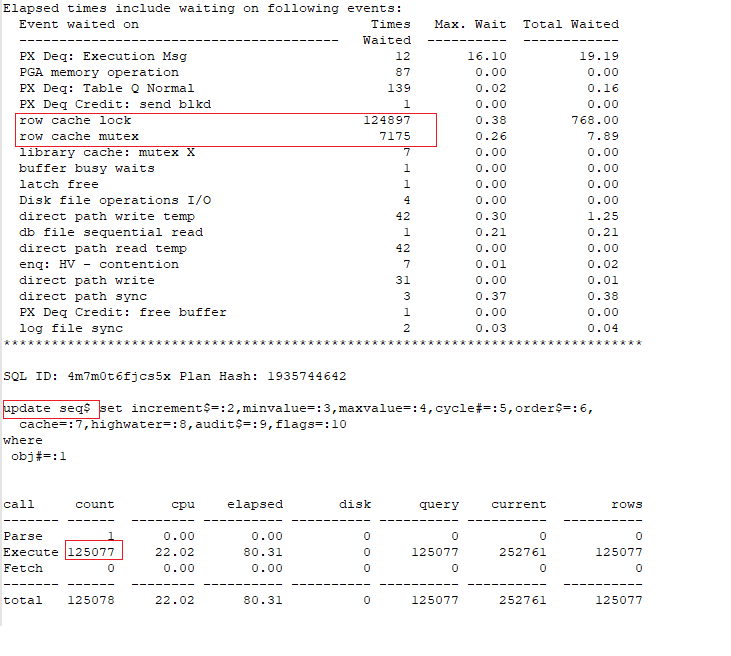
After caching the sequence, the insert works very efficiently.
