When deleting data from a table, Oracle checks for each deleted row whether there are other rows that depend on the deleted one. So oracle will scan (or use indexes if they exist) all tables that have a foreign key pointing on the target table, to see whether the deleted row has child rows. So Deleting must not cause orphans. Oracle will do a full scan on the child tables if no indexes are defined on the foreign keys columns. This is of course very inefficient if the child tables are big.
But what if you just want to delete data from the parent table that does not exist in the child tables? Like this „delete from tbl_parent where not exists (select * from tbl_child)„. You would expect Oracle to not recheck that the deleted records does not have any dependent records in the child tables.
Let’s illustrate this with an example
CREATE TABLE tbl_parent (ID NUMBER PRIMARY KEY) ;
CREATE TABLE tbl_child (ID NUMBER , id_parent NUMBER, CONSTRAINT fk_tbl_child_parent FOREIGN KEY (id_parent) REFERENCES tbl_parent(ID)) ;
INSERT INTO tbl_parent SELECT ROWNUM FROM dual CONNECT BY LEVEL < 101;
INSERT INTO tbl_child SELECT ROWNUM, ROWNUM + 50 FROM dual CONNECT BY LEVEL < 51;
COMMIT;
And we try to delete all rows from the parent table that does not exist in the child table. We enable the event 10046 and analyze the trace file.
ALTER SESSION SET EVENTS '10046 trace name context forever, level 8';
delete from tbl_parent where id not in (select id_parent from tbl_child);
commit;
ALTER SESSION SET EVENTS '10046 trace name context off';
In the trace file:
SQL ID: 8uucqtmzuqnhz Plan Hash: 2719173255 delete from tbl_parent where id not in (select id_parent from tbl_child) call count cpu elapsed disk query current rows ——- —— ——– ———- ———- ———- ———- ———- Parse 1 0.00 0.00 0 4 2 0 Execute 1 0.00 0.00 0 11 256 50 Fetch 0 0.00 0.00 0 0 0 0 ——- —— ——– ———- ———- ———- ———- ———- total 2 0.01 0.00 0 15 258 50 Misses in library cache during parse: 1 Optimizer mode: ALL_ROWS Parsing user id: 107 Number of plan statistics captured: 1 Rows (1st) Rows (avg) Rows (max) Row Source Operation ———- ———- ———- ————————————————— 0 0 0 DELETE TBL_PARENT (cr=361 pr=0 pw=0 time=9025 us starts=1) 50 50 50 HASH JOIN ANTI NA (cr=11 pr=0 pw=0 time=285 us starts=1 cost=5 size=2600 card=100) 100 100 100 INDEX FAST FULL SCAN SYS_C0021393 (cr=4 pr=0 pw=0 time=24 us starts=1 cost=2 size=1300 card=100)(object id 100084) 50 50 50 TABLE ACCESS FULL TBL_CHILD (cr=7 pr=0 pw=0 time=17 us starts=1 cost=3 size=650 card=50) Elapsed times include waiting on following events: Event waited on Times Max. Wait Total Waited —————————————- Waited ———- ———— Disk file operations I/O 1 0.00 0.00 log file sync 1 0.00 0.00 PGA memory operation 1 0.00 0.00 SQLNet message to client 1 0.00 0.00 SQLNet message from client 1 0.00 0.00
SQL ID: g59tya9raw21s Plan Hash: 3669815686 select /*+ all_rows */ count(1) from „TESTER“.“TBL_CHILD“ where „ID_PARENT“ = :1 call count cpu elapsed disk query current rows ——- —— ——– ———- ———- ———- ———- ———- Parse 1 0.00 0.00 0 0 0 0 Execute 50 0.00 0.00 0 0 0 0 Fetch 50 0.00 0.00 0 350 0 50 ——- —— ——– ———- ———- ———- ———- ———- total 101 0.00 0.00 0 350 0 50 Misses in library cache during parse: 1 Misses in library cache during execute: 1 Optimizer mode: ALL_ROWS Parsing user id: SYS (recursive depth: 1) Number of plan statistics captured: 1 Rows (1st) Rows (avg) Rows (max) Row Source Operation ———- ———- ———- ————————————————— 1 1 1 SORT AGGREGATE (cr=7 pr=0 pw=0 time=27 us starts=1) 0 0 0 TABLE ACCESS FULL TBL_CHILD (cr=7 pr=0 pw=0 time=23 us starts=1 cost=2 size=13 card=1)
SQL ID: 9pgdf32vu0h3c Plan Hash: 0 commit
So we see that for each deleted row oracle do the following check:
select /*+ all_rows */ count(1)
from
"TESTER"."TBL_CHILD" where "ID_PARENT" = :1
So oracle did not realize that this check is superfluous.
There are many ways to read comma-separated line into a array: Using PL/SQL Functions, XMLTABLE … However in this example I use only the famous select * from dual The goal is to transform the String ‚val1,val2,….,val11‘ into varchar2list.
declare
v_values sys.odcivarchar2list := sys.odcivarchar2list();
begin
with myline as
(select 'val1,val2,val3,val4,val5,val6,val7,val8,val9,val10,val11,' text from dual)
select case
when a < b then
substr(text, b)
else
substr(text, b, a - b)
end text
bulk collect
into v_values
from (select rownum n,
instr(text, ',', 1, rownum) a,
decode(rownum, 1, 1, instr(text, ',', 1, rownum - 1) + 1) b,
text
from myline
where decode(rownum, 1, 1, instr(text, ',', 1, rownum - 1)) > 0
connect by level < 100);
for i in 1 .. v_values.count loop
dbms_output.put_line(v_values(i));
end loop;
end;
In some cases, data versioning is used at the record level. This is especially useful because you can version tables independently. You only need to version those records, that have changed, without changing dependent records from other tables. This by using two date columns in each table „version_from“ and „version_to“. So that there is always exactly one version of a record for a given time from each table. This reduces the memory space and the IOs.
Because in any given time there is at most only one version of a record per table, joining two tables in a given time is easy. However to join the tables independently for a given time (all changes across two tables) is little bit tricky. In this Blog I will show you how to do that.
For instance let’s create two tables „tbl_a“ and „dim_1“. The two tables should be joined using the columns tbl_a.dim_1_id and dim_1.id.
-- create table tbl_a
create table tbl_a (
id number
,valid_from timestamp(6)
,valid_to timestamp(6)
,dim_1_id number
,some_info varchar2(10)
);
--create table dim_1
create table dim_1 (
id number
,valid_from timestamp(6)
,valid_to timestamp(6)
,some_value number
);
Let’s generate some data:
insert into tbl_a
select 123456 id,
systimestamp + numtodsinterval(1, 'SECOND') +
numtodsinterval(rownum - 1, 'HOUR') valid_from,
systimestamp + numtodsinterval(rownum, 'HOUR') valid_to,
123 dim_1_id,
decode(mod(rownum,3),1,'value1',2,'value2','value3') some_value
from dual connect by level < 4
union all
select 123456 id,
systimestamp + numtodsinterval(1, 'SECOND') +
numtodsinterval(rownum - 1, 'HOUR') valid_from,
systimestamp + numtodsinterval(rownum, 'HOUR') valid_to,
124 dim_1_id,
decode(mod(rownum,3),1,'value1',2,'value2','value3') some_value
from dual connect by level < 4
union all
select 123456 id,
systimestamp + numtodsinterval(1, 'SECOND') +
numtodsinterval(rownum - 1, 'HOUR') valid_from,
systimestamp + numtodsinterval(rownum, 'HOUR') valid_to,
125 dim_1_id,
decode(mod(rownum,3),1,'value1',2,'value2','value3') some_value
from dual connect by level < 4
;
commit;
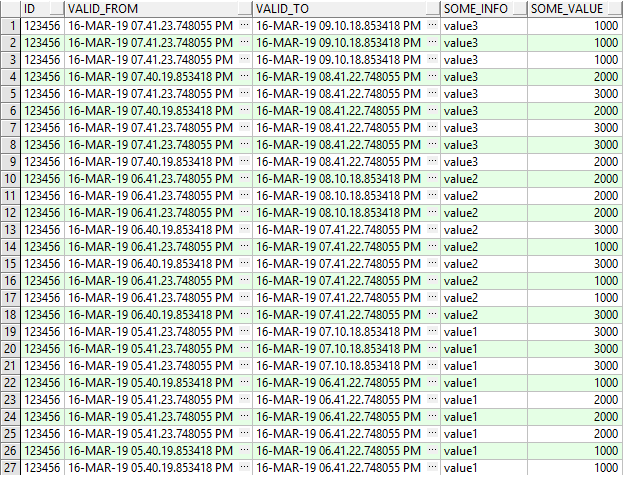
select * from tbl_a order by valid_to desc select * from dim_1 order by id,valid_to des
Joining the tables at given a time is straightforward
select *
from tbl_a a
join dim_1 b
on a.dim_1_id = b.id
and to_timestamp('16.03.2019 18:42:00', 'dd.mm.yyyy hh24:mi:ss') between
a.valid_from and a.valid_to
and to_timestamp('16.03.2019 18:42:00', 'dd.mm.yyyy hh24:mi:ss') between
b.valid_from and b.valid_to
join result at to_timestamp(‚16.03.2019 18:42:00‘, ‚dd.mm.yyyy hh24:mi:ss‘)
But joining the tables without specifying a given time is little bit tricky:
select a.id,
least(a.valid_from, b.valid_from) valid_from,
greatest(a.valid_to, b.valid_to) valid_to,
a.some_info,
b.some_value
from tbl_a a
join dim_1 b
on a.dim_1_id = b.id
and greatest(a.valid_from, b.valid_from) < least(a.valid_to, b.valid_to)
order by 3 desc
Join result without specifying a time (all versions change across both tables)
Today I want to show you how I analyse the referential integrity in Oracle. First only for one level and then using an SQL to find the entire hierarchy leading up to a specific table. Certainly you can do this using tools, but here only SQL is used.
The referential integrity in Oracle is ensured by using foreign keys. As an an example we create three tables parent_tbl, child_tbl1 and child_tbl2. Both child_tbl1 and child_tbl2 tables have foreign keys pointing on parent_tbl table.
With the following statement we find the tables that have foreign keys pointing on the parent_tbl table.
SELECT A.OWNER,
A.TABLE_NAME,
A.CONSTRAINT_NAME,
A.R_CONSTRAINT_NAME,
A.CONSTRAINT_TYPE
FROM USER_CONSTRAINTS A
JOIN USER_CONSTRAINTS B
ON A.OWNER = B.OWNER
AND A.R_CONSTRAINT_NAME = B.CONSTRAINT_NAME
WHERE B.TABLE_NAME = 'PARENT_TBL'
AND A.CONSTRAINT_TYPE = 'R'
OWNER TABLE_NAME CONSTRAINT_NAME R_CONSTRAINT_NAME CONSTRAINT_TYPE
1 TESTER CHILD_TBL2 FK_CHILD_TBL2 PK_PARENT_TBL R
2 TESTER CHILD_TBL1 FK_CHILD_TBL1 PK_PARENT_TBL R
If you are interested to know also the columns involved in the foreign key relationship:
WITH CONS AS
(SELECT A.OWNER,
A.TABLE_NAME,
A.CONSTRAINT_NAME,
A.R_CONSTRAINT_NAME,
B.TABLE_NAME R_TABLE_NAME,
A.CONSTRAINT_TYPE
FROM USER_CONSTRAINTS A
JOIN USER_CONSTRAINTS B
ON A.OWNER = B.OWNER
AND A.R_CONSTRAINT_NAME = B.CONSTRAINT_NAME
WHERE B.TABLE_NAME = 'PARENT_TBL'
AND A.CONSTRAINT_TYPE = 'R')
SELECT A.*, B.COLUMN_NAME, B.POSITION
FROM CONS A
JOIN USER_CONS_COLUMNS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.CONSTRAINT_NAME = B.CONSTRAINT_NAME
OWNER TABLE_NAME CONSTRAINT_NAME R_CONSTRAINT_NAME R_TABLE_NAME CONSTRAINT_TYPE COLUMN_NAME POSITION
1 TESTER CHILD_TBL1 FK_CHILD_TBL1 PK_PARENT_TBL PARENT_TBL R PARENT_TBL_ID2 2
2 TESTER CHILD_TBL1 FK_CHILD_TBL1 PK_PARENT_TBL PARENT_TBL R PARENT_TBL_ID 1
3 TESTER CHILD_TBL2 FK_CHILD_TBL2 PK_PARENT_TBL PARENT_TBL R PARENT_TBL_ID2 2
4 TESTER CHILD_TBL2 FK_CHILD_TBL2 PK_PARENT_TBL PARENT_TBL R PARENT_TBL_ID 1
The following statement return only one row per table. (so you can use it directly to generate ddl for the fk)
WITH CONS AS (SELECT A.OWNER,
A.TABLE_NAME,
A.CONSTRAINT_NAME,
B.TABLE_NAME R_TABLE_NAME,
A.R_CONSTRAINT_NAME,
A.CONSTRAINT_TYPE
FROM USER_CONSTRAINTS A
JOIN USER_CONSTRAINTS B
ON A.OWNER = B.OWNER
AND A.R_CONSTRAINT_NAME = B.CONSTRAINT_NAME
WHERE B.TABLE_NAME = 'PARENT_TBL'
AND A.CONSTRAINT_TYPE = 'R'),
CONS_R_COL AS
(SELECT A.*, B.COLUMN_NAME, B.POSITION
FROM CONS A
JOIN USER_CONS_COLUMNS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.CONSTRAINT_NAME = B.CONSTRAINT_NAME), INFO_V AS
(SELECT RC.OWNER,
RC.TABLE_NAME,
RC.CONSTRAINT_NAME,
RC.COLUMN_NAME,
RC.R_TABLE_NAME,
RC.R_CONSTRAINT_NAME,
RP.COLUMN_NAME R_COLUMN_NAME,
RC.POSITION
FROM CONS_R_COL RC
JOIN USER_CONS_COLUMNS RP
ON RC.OWNER = RP.OWNER
AND RC.R_TABLE_NAME = RP.TABLE_NAME
AND RC.POSITION = RP.POSITION) SELECT OWNER,
TABLE_NAME,
CONSTRAINT_NAME,
LISTAGG(COLUMN_NAME, ',') WITHIN GROUP(ORDER BY POSITION) COLS,
R_TABLE_NAME,
R_CONSTRAINT_NAME,
LISTAGG(R_COLUMN_NAME, ',') WITHIN GROUP(ORDER BY POSITION) R_COLS
FROM INFO_V
GROUP BY OWNER,
TABLE_NAME,
CONSTRAINT_NAME,
R_TABLE_NAME,
R_CONSTRAINT_NAME
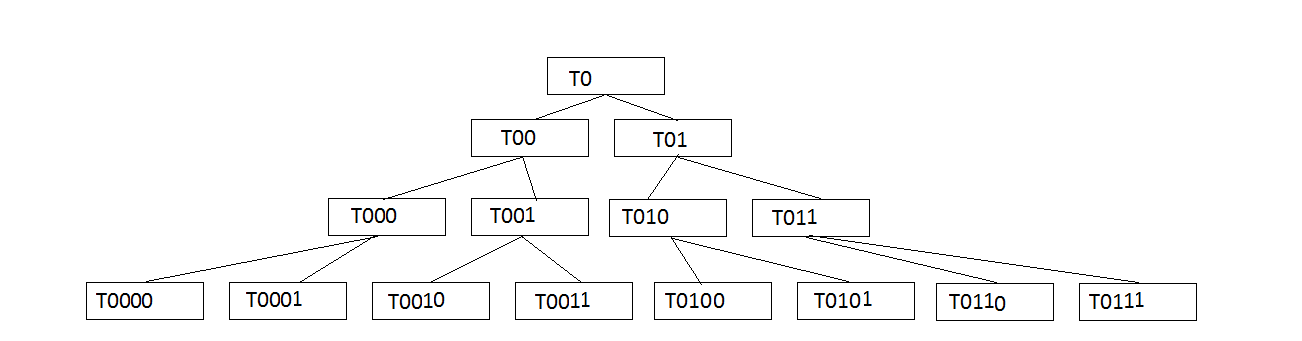
So far so good. But what can be interesting is to find the whole hierarchy leading up to a table. Let’s create a few tables that make up a binary tree. Starting from the table T0. This has two child tables, each one with two child tables. We stop at level 3. in total we have 15 tables. With the following block you can first visualize this tree.
DECLARE
lvl BINARY_INTEGER := 0;
deep BINARY_INTEGER := 2;
procedure LOG(msg VARCHAR2,n binary_integer DEFAULT 0) IS
BEGIN
dbms_output.put_line(rpad(' ' ,n*2)||msg);
END;
PROCEDURE cre_childs(parent_tbl VARCHAR2, l binary_integer) IS
BEGIN
FOR j IN 0..1 LOOP
LOG(parent_tbl||j,l);
IF l <= deep THEN
cre_childs(parent_tbl ||j,l+1);
END IF;
END LOOP;
END;
BEGIN
LOG('T0');
cre_childs('T0',1);
END;
With the following statement you get the whole hierarchy leading up to the table T0:
WITH core AS
(SELECT b.table_name tbl_parent,
a.TABLE_NAME tbl_child,
b.constraint_name constraint_parent,
a.CONSTRAINT_NAME constraint_child
FROM user_constraints a
JOIN user_constraints b
ON a.R_CONSTRAINT_NAME = b.CONSTRAINT_NAME
WHERE a.CONSTRAINT_TYPE = 'R'),
tbl0 AS
(SELECT tbl_parent,
tbl_child,
level l,
connect_by_iscycle iscycl,
constraint_parent,
constraint_child
FROM core
START WITH tbl_parent = 'T0' ------ Root table
CONNECT BY NOCYCLE PRIOR tbl_child = tbl_parent),
tbl AS
(SELECT tbl_parent,
tbl_child,
MAX(iscycl) iscycl,
constraint_parent,
constraint_child,
l
FROM tbl0
GROUP BY tbl_parent,tbl_child,constraint_parent,constraint_child,l),
tbl2 as
(SELECT tbl_parent, tbl_child, constraint_parent, constraint_child,0 iscycl, l level_
FROM tbl
UNION all
SELECT tbl.tbl_child, tbl.tbl_child, core.constraint_parent, core.constraint_child,1, l level_
FROM tbl
JOIN core
ON tbl.tbl_child = core.tbl_parent and tbl.tbl_child = core.tbl_child WHERE iscycl = 1
AND core.constraint_parent <> tbl.constraint_parent),
tmp as
(SELECT tbl_parent table_name, constraint_parent constraint_name,iscycl
FROM tbl2
UNION
SELECT tbl_child, constraint_child,iscycl FROM tbl2),
tmp2 as
(SELECT c.table_name, c.constraint_name, c.column_name, position,iscycl
FROM (select table_name,constraint_name,column_name,position from user_cons_columns
) c
JOIN tmp
ON c.table_name = tmp.table_name
AND c.constraint_name = tmp.constraint_name),
tmp3 as
(SELECT table_name,
constraint_name,
listagg(column_name,',') WITHIN GROUP(ORDER BY position) cols,
MAX(iscycl) iscycl
FROM tmp2
GROUP BY table_name, constraint_name)-- main select SELECT distinct tbl2.iscycl,tbl2.tbl_parent,tbl2.tbl_child,p_col.cols p_cols , c_col.cols c_cols ,level_
FROM tbl2
JOIN tmp3 p_col
ON tbl2.tbl_parent = p_col.table_name
AND tbl2.constraint_parent = p_col.constraint_name
JOIN tmp3 c_col
ON tbl2.tbl_child = c_col.table_name
AND tbl2.constraint_child = c_col.constraint_name
order by level_,tbl2.iscycl DESC
Here’s my experience with a performance problem in the Oracle database. After several months of work on a product and after successful tests, it was time to carry out the integration tests at the customer. Now the customer has noticed that the GUI (JAVA) is quite slow in some situations.
What happened then?! Everything works for us perfect. What is special about the customer? Now I was assigned to analyze the problem.
The first thing I did was to look in our application log and to compare it with the logs in our UAT environment. Surprisingly, the suspicious SQL was easy to find. It was a simple SQL. It should return at most dozens of records and is finished in our UAT environmentin in one second. But by the customer takes more than a minute. The Statement should be called several times, each time it takes more than a minute. This of course makes the GUI very slow.
The SQL ist:
WITH CFG_TBL_AS AS
(SELECT
OWNER, TABLE_NAME, COLUMN_NAME, FUNCTION_NAME, TABLE_NAME_NEW
FROM TMP_$_ANONY$CONFIG$
WHERE TABLE_NAME_NEW IS NOT NULL)
SELECT A.TABLE_NAME, A.COLUMN_NAME, B.TABLE_NAME_NEW, B.FUNCTION_NAME
FROM ALL_TAB_COLS A
LEFT JOIN CFG_TBL_AS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE (A.OWNER, A.TABLE_NAME) IN
(SELECT OWNER, TABLE_NAME FROM CFG_TBL_AS)
ORDER BY A.TABLE_NAME, A.COLUMN_ID
looks easy. I get the Execute Plan from the Customer. I will only show the important here. (which is actually the problem)
It looks like oracle is trying to materialize a subquery. (A powrful feature of With Clause is materializing subqueries) In our environment the execute plan looks like this
Then I tried the SQL with the materialize hint and as expected I get the same execute paln and it takes also more than one minutes.
WITH CFG_TBL_AS AS
(SELECT --+materialize
OWNER, TABLE_NAME, COLUMN_NAME, FUNCTION_NAME, TABLE_NAME_NEW
FROM TMP_$_ANONY$CONFIG$
WHERE TABLE_NAME_NEW IS NOT NULL)
SELECT A.TABLE_NAME, A.COLUMN_NAME, B.TABLE_NAME_NEW, B.FUNCTION_NAME
FROM ALL_TAB_COLS A
LEFT JOIN CFG_TBL_AS B
ON A.OWNER = B.OWNER
AND A.TABLE_NAME = B.TABLE_NAME
AND A.COLUMN_NAME = B.COLUMN_NAME
WHERE (A.OWNER, A.TABLE_NAME) IN
(SELECT OWNER, TABLE_NAME FROM CFG_TBL_AS)
ORDER BY A.TABLE_NAME, A.COLUMN_ID
Why is it even trying to materialize a few records (which fit into a single block)? And why should something take forever? But the important question for me was why does the statement behave as if the hint is inline?
This is because of the hidden system parameter: _with_subquery. It turns out that this is set to inline on our UAT environment!
ALTER SYSTEM SET "_with_subquery" = INLINE;
Someone forgot to remove this parameter, so we could not spot this issue before delivery. After adding the hint everythings work fine.
The following block should provide the commands to disable the foreign keys pointing on a table. It works wonderfully in 11.2.0.4 and 12.1.0.2 but not on 12.2.0.1. Does not trigger an error but also no results. You can test it, just replace ‚MYTABLE‘ with a table that has foreign key pointing on it.
DECLARE
-- table that has Foreignkey pointing on it
v_tbl_name VARCHAR2(30) := 'MYTABLE';
CURSOR get_massdata_tableinfo
IS
SELECT v_tbl_name table_name FROM dual
;
CURSOR get_fks(par_target_table user_tables.table_name%TYPE)
IS
WITH
user_constr AS
(
SELECT *
FROM all_constraints
WHERE owner = sys_context('USERENV', 'CURRENT_SCHEMA')
)
SELECT r.constraint_name,
r.table_name
FROM user_constr r,
user_constr t
WHERE t.table_name = par_target_table
AND t.constraint_type = 'P'
AND t.constraint_name = r.r_constraint_name
;
BEGIN
FOR crec IN get_massdata_tableinfo
LOOP
--
dbms_output.put_line('Table Name ' || crec.table_name);
-- disable FK´s pointing to table
FOR rec IN get_fks(crec.table_name) --no rows in 12.2.0.1 (but it works in 11.2.0.4 and 12.1.0.2)
LOOP
dbms_output.put_line('ALTER TABLE ' || rec.table_name ||
' DISABLE CONSTRAINT ' || rec.constraint_name);
END LOOP;
END LOOP;
END;
If I call the SQL directly, then I get records.
WITH
user_constr AS
(
SELECT *
FROM all_constraints
WHERE owner = sys_context('USERENV', 'CURRENT_SCHEMA')
)
SELECT r.constraint_name,
r.table_name
FROM user_constr r,
user_constr t
WHERE t.table_name = 'MY_TABLE'
AND t.constraint_type = 'P'
AND t.constraint_name = r.r_constraint_name
Is this a bug ?
It looks like the problem is because of the oracle patch 22485591. It works in a 12.2.0.1 without this patch. In addition, a strange thing: When I add the hint no_merge to the following Statement it works also with the path 22485591.
CURSOR get_fks(par_target_table user_tables.table_name%TYPE)
IS
WITH
user_constr AS
(
SELECT /*+ no_merge */ * -- this is very strange
FROM all_constraints
WHERE owner = sys_context('USERENV', 'CURRENT_SCHEMA')
)
SELECT r.constraint_name,
r.table_name
FROM user_constr r,
user_constr t
WHERE t.table_name = par_target_table
AND t.constraint_type = 'P'
AND t.constraint_name = r.r_constraint_name
;
I posted the problem in freelists.org and I get this response from Jonathan Lewis:
—————————— — „deep dive“ —————————— Okay, I ran your test and got no output on 12.2.01 Traced it (10046 level 4) Found that the query against all_constraints went parallel and returned no data, so added a /*+ noparallel */ hint to the query, then (belts and braces) „alter session disable parallel query;“ Ran the test again – got the expected result. It looks like the parallel execution loses the value of sys_context. I would check whether 12.1.0.2 and 11.2.0.4 ran the query parallel or whether they ran it serially, and if they’re running t serially check what happens if you force it parallel.
—————– — After the no_merge comment: —————–
That (ed. the no_merge) may be luck rather than anything else. I just tried the same thing and still saw the problem (and parallel execution). In your case it’s possible that the presence of the no_merge hint resulted in Oracle materializing the subquery and maybe that made it run serially – i.e. it was about object_statistics rather than functionality.
P.S. Looking at the execution plans, my 12.2 (corrected from 12.1) is translating all_constraints to a query involving int$int$DBA_CONSTRAINTS, while the 12.1 query is a „more traditional“ massive join of lots of tables – so the base problem seems to start with the appearance of a CDB-mechanism of all_constraints. (I’m running 12.2. from a PDB, while the 12.1 is non-PDB database)
In this post I would like to briefly introduce how I dynamically generate a SQL to find diff of two tables. When optimizing a SQL Statement to get better performance, in most cases is not only enough to add (or remove) a few hints, but you have to rewrite the whole SQL statement. This is too risky and can cause the new statement to produce a very different result. That’s why you have to compare the results of both statements. One saves the result of the SQL before the optimization in a table e.g. table_a. And the result of SQL after optimization in the table Table_b. The difference is the result of the following SQL:
Select ‘table_a’ src,t.* from (Select * from table_a minus select * from table_b)
Union all
Select ‘table_b’ src,t.* from (Select * from table_b minus select * from table_a)
This will not work if the tables contain LOB objects. You can exclude the LOB objects from the comparison. But if they were quite relevant, you could use a hash function. The following PL / SQL block dynamically generates the Diff SQL and use the dbms_crypto.hash function:
DECLARE
tbl_a VARCHAR2(30):= 'TABLE_a';
tbl_b VARCHAR2(30):= 'TABLE_b';
cols VARCHAR2(32767);
stmt VARCHAR2(32767);
BEGIN
FOR rec IN (SELECT * FROM user_tab_columns WHERE table_name = 'JURISTISCHE_PERSON' ORDER BY column_id) LOOP
cols := cols || CASE WHEN rec.data_type IN ('CLOB','BLOB') THEN 'dbms_crypto.hash( utl_raw.cast_to_raw('||rec.column_name||'), 2) as ' || rec.column_name
ELSE rec.column_name END||','||CHR(10);
END LOOP;
cols := rtrim(cols,','||CHR(10));
stmt := 'select '''||tbl_a||''' src,t.* from (select '||cols|| ' from ' || tbl_a || ' minus select '||cols|| ' from ' || tbl_b||') t
union all
select '''||tbl_b||''',t.* from (select '||cols|| ' from ' || tbl_b || ' minus select '||cols|| ' from ' || tbl_a||') t';
dbms_output.put_line(stmt);
END;